The biggest hurdle with subtitles is timing. Splitting text into chunks long enough to be readable on screen is a whole profession, and we really didn't have the time and resources for it.
One (admittedly brutal) solution is to use YouTube's own automatic subtitles. Every time a video is uploaded, YouTube uses a speech recognition system in order to turn audio into text, and then split it automatically into subtitles.
As you can see, it's not perfect, but it gets the job done.
In order to extract the subtitles we use an open source tool called Google2SRT, which you can download here. It's a Java application, so it runs everywhere (Windows, Mac, Linux) and without installation.
The tool is pretty self explanatory: you just need to input the URL of the video, press read, then pick the desired language(s) and click Go!
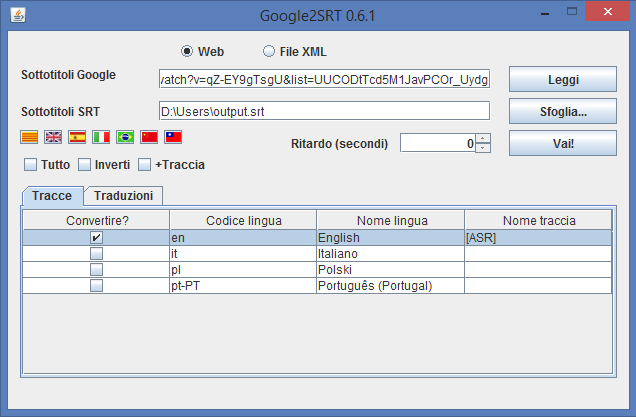
At that point, you should have a .SRT file, which you can open with any plain text editor like notepad and looks like that:
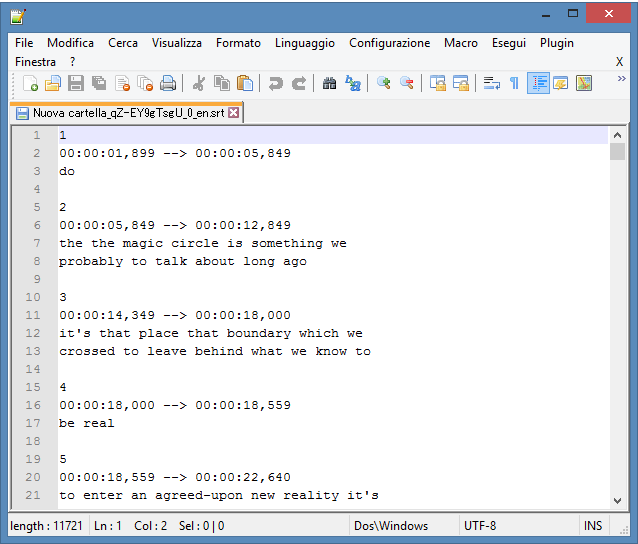
Again, pretty self explanatory. Each entry is marked by an ordinal number, start and end times, and the subtitle itself.
As usual, we work inside memoQ, so we import the file as plain text and then, in order to get the control codes out of the way fast, we just sort everything in alphabetical order, select the control codes, copy to target and lock.
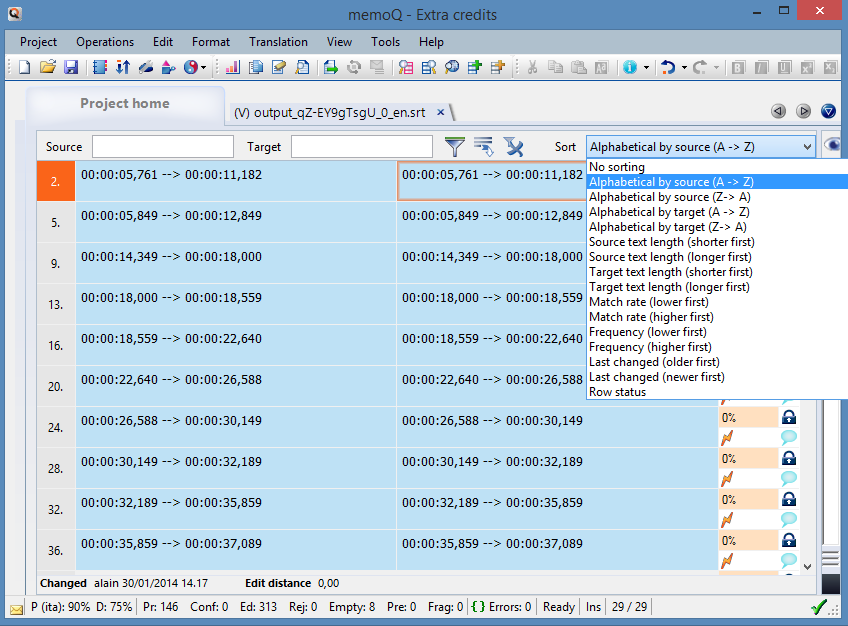
If you don't have memoQ, you can achieve a similar result with Excel.
- Copy the whole content of the .SRT file and paste it into column B of a new Excel sheet
- In column A type 1, 2, 3 in the first three lines, then drag and drop until all the lines in column B have a number on their side (Excel will continue the series automatically)
- Sort column B alphabetically, then select all the cells that contain the control codes and drag them into column C
- Sort column A alphabetically in order to restore the original order
- Voilà! All the control codes are now copied into column C. You can now start translating into column C, and you can even apply a "Blank lines" filter in order to remove codes from view
- When you're done, just copy and paste column C into the original .SRT file
During the translation process you will meet three main issues.
The speech recognition engine is pretty good (especially with a series like EC which has only Dan's voice and no music background), but it does make some mistakes you should probably correct in the source.
Also, YouTube applies no punctuation at all. Actual movie subtitles tend to remove some of the punctuation too, so our solution was to implement only the punctuation signs that are strictly necessary. For example, we use full stops to separate sentences that appear together on screen, but we don't put them at the end of each sentence. It's a detail, but it makes the text more readable while reducing our workload.
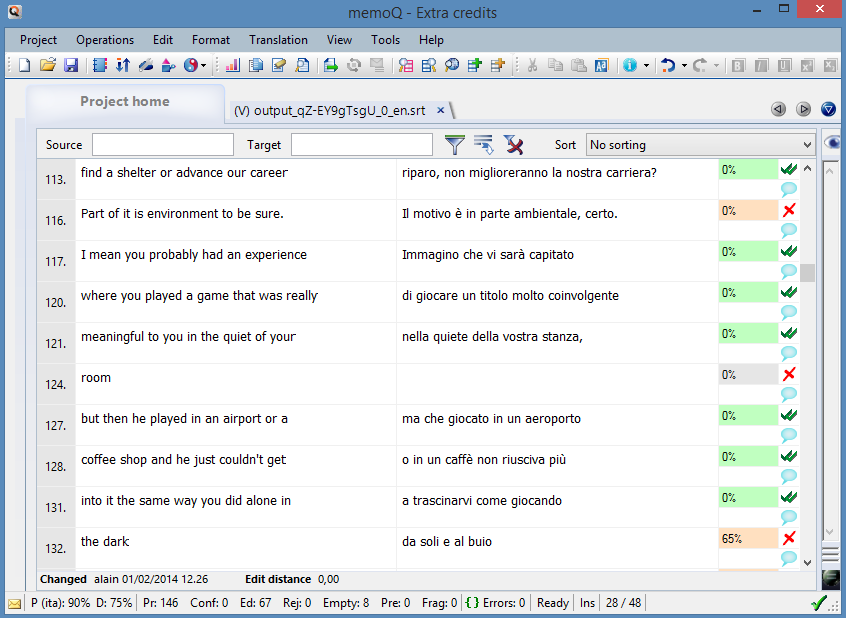
The final issue is subtitles that end up being too short. In the example below, it doesn't make much sense to have "room" appearing alone at line 124, so we just merged it into the translation above.
Once you are done (and have proofread & spellchecked thrice), you are ready to export as .SRT
As a final step, you should "absorb" the subtitles you decided to remove, by copying their end time on the subtitle before and then removing them. Incidentally, this also means that your .SRT file will skip an ordinal number, but YouTube doesn't seem to mind.
That's it! All you need to do now is upload your SRT file on YouTube
As you can see from the video above, a couple of timings can be slightly off, but tweaking them is still way faster and easier than doing a full timing.
Thanks for reading and enjoy the show!